|
Ameer Haj-Ali We're building a generational AI company in San Francisco and seeking exceptional AI engineering talent to join us in-office. We received subtstantial oversubscribed funding -- by world class visionaries, Turing Award winners, and the best Silicon Valley VCs. If you are cracked and want to work with extremely ambitious and talented individuals reach out to me with your 2-3 most impressive accomplishments! Before starting my company I Cofounded & Incubated Companies with Elad Gil, Eric Schmidt, and Jared Kushner. Built first products, close first deals, and hired founding team. Helped get the valuation to more than $100M. Previously, I was part of the founding team of Anyscale where I helped grow the company from 0 to 150 and headed Platform, Infrastructure, and Gen AI organizations and the major releases, such as Multi-Cloud Infrastructure, General Availability, LLM Endpoints. I completed my CS PhD in 2 years (the fastest in the university) at UC Berkeley in AI and System working with Professors Ion Stoica and Krste Asanovic. I received the valedictorian honor from the Technion twice for my M.Sc. and B.Sc. |

|
Professional ExperienceI thrive in building and conducting lean, fast executing, high-performing teams to achieve ambitious goals. |

|
Founding Engineer. Head of Platform, Infrastructure & Endpoints Engineering, 2019-2024.
Helped grow the company from 0 to 150. Throughout my career at Anyscale, I built teams responsible for Ray Serve/Inference, Ray Autoscaler and Cluster (video here), Ray Client, Anyscale Services, Gen AI, Multi-cloud Infrastructure, KubeRay, and proprietary vLLM. |

|
AI Researcher in the Brain Inspired Computing Lab (internship), 2019. "NeuroVectorizer: End-to-End Vectorization with Deep Reinforcement Learning". Published in CGO 2020 (the premier conference in compilers). "RLDRM: Closed Loop Dynamic Intel RDT Resource Allocation with Deep Reinforcement Learning". Published in NetSoft 2020 (received Best Paper Award). "A View on Deep Reinforcement Learning in System Optimization". Available on arXiv. |

|
Chip Design Engineer, 2015-2016. Worked during my studies on creating design and automation tools that facilitated the formal and dynamic verification process. Worked especially with Python, scripting languages, C++, and Verilog. |
Publications |

|
Gemmini: Enabling Systematic Deep-Learning Architecture Evaluation via Full-Stack Integration
Hasan Genc, Seah Kim, Alon Amid, Ameer Haj-Ali, Vighnesh Iyer, Pranav Prakash, Jerry Zhao, Daniel Grubb, Harrison Liew, Howard Mao, Albert Ou, Colin Schmidt, Samuel Ste, John Wright, Ion Stoica, Jonathan Ragan-Kelley, Krste Asanovic, Borivoje Nikolic, Yakun Sophia Shao DAC 2021. Nominated for Best Paper Award. project page / video / full tutorial / paper / arXiv We present Gemmini, an open-source, systolic array based full-stack (hardware and software) DNN accelerator generator. |

|
TenSet: A Large-scale Program Performance Dataset for Learned Tensor Compilers
Lianmin Zheng, Ruochen Liu, Junru Shao, Tianqi Chen, Joseph E. Gonzalez, Ion Stoica, Ameer Haj Ali NeurIPS 2021. project page / paper TenSet is a large-scale tensor program performance dataset featuring 52 million records across six hardware platforms, offering in-depth analysis on learning and evaluating cost models that can improve tensor compiler search times by up to tenfold. |
|
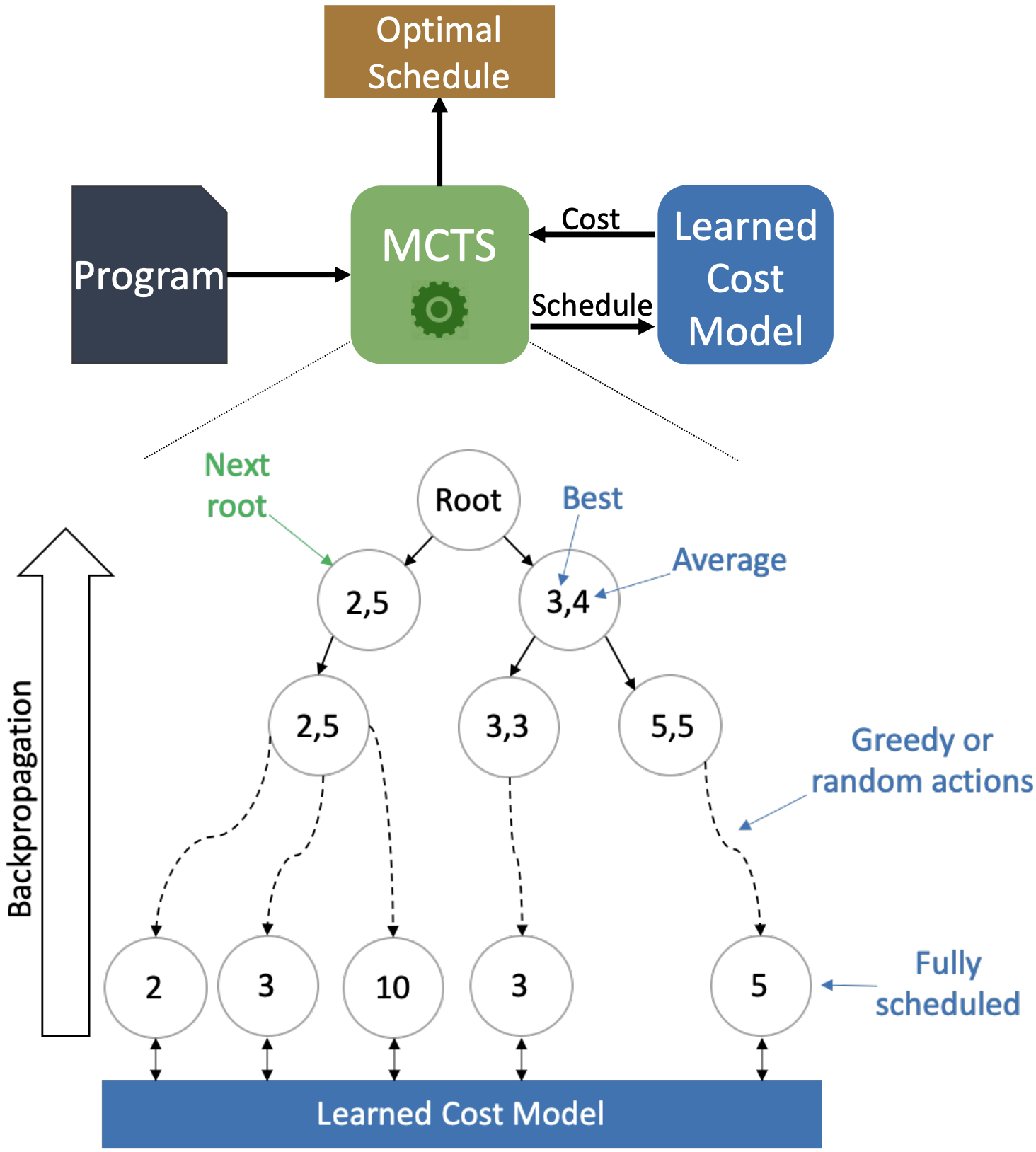
ProTuner: Tuning Programs with Monte Carlo Tree Search
Ameer Haj-Ali, Hasan Genc, Qijing Huang, William Moses, John Wawrzynek, Krste Asanović, Ion Stoica arXiv We show that Monte Carlo Tree Search (MCTS), when applied to the challenging task of tuning programs for deep learning and image processing using the Halide framework, outperforms the state-of-the-art beam search by evaluating complete schedules and incorporating real-time execution measurements. |

|
Ansor: Generating High-Performance Tensor Programs for Deep Learning
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, Joseph Gonzalez, Ion Stoica OSDI 2020. Video / paper / arXiv We introduce Ansor, a tensor program generation framework that surpasses existing methods by exploring a broader range of optimization combinations and fine-tuning them with evolutionary search and a learned cost model, significantly enhancing the execution performance of deep neural networks on various hardware platforms. |
|
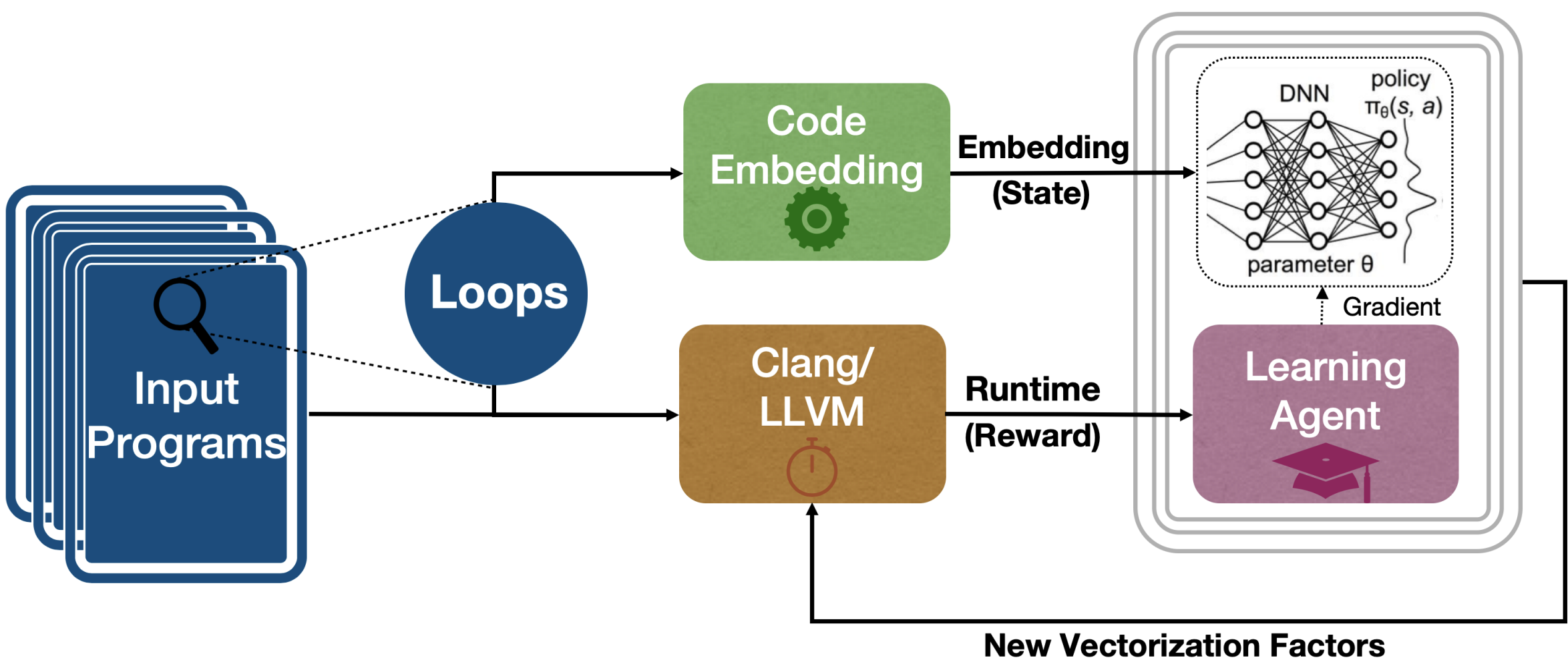
NeuroVectorizer: End-to-End Vectorization with Deep Reinforcement Learning
Ameer Haj-Ali, Nesreen Ahmed, Ted Willke, Sophia Shao, Krste Asanovic, Ion Stoica CGO 2020. paper / arXiv / code / video NeuroVectorizer is a framework that uses deep reinforcement learning to automate the vectorization process in compilers, significantly improving performance on modern processors. Work done in a summer internship at Intel Labs. |

|
AutoPhase: Juggling HLS Phase Orderings in Random Forests with Deep Reinforcement Learning
Ameer Haj-Ali, Qijing Huang, William Moses, John Xiang, Krste Asanovic, John Wawrzynek, Ion Stoica MLSys 2020. paper / arXiv / code / video AutoPhase leverages deep reinforcement learning to efficiently explore phase ordering in high-level synthesis (HLS), achieving optimal performance for various applications by dynamically learning effective phase sequences. |

|
AutoCkt: Deep Reinforcement Learning of Analog Circuit Designs
Keertana Settaluri, Ameer Haj-Ali, Qijing Huang, Suhong Moon, Kourosh Hakhamaneshi, Ion Stoica, Krste Asanovic, Borivoje Nikolic DATE 2020. code / paper / arXiv AutoCkt introduces a deep reinforcement learning-based approach to automate and optimize the design of analog circuits, demonstrating substantial improvements in design quality and efficiency. |

|
RLDRM: Closed Loop Dynamic Cache Allocation with Deep Reinforcement Learning for Network Function Virtualization
Bin Li, Yipeng Wang, Ren Wang, Charlie Tai, Ravi Iyer, Zhu Zhou, Andrew Herdrich, Tong Zhang, Ameer Haj-Ali, Ion Stoica, Krste Asanovic NetSoft 2020. Best Paper Award. paper RLDRM employs deep reinforcement learning to dynamically allocate cache resources in network function virtualization, enhancing system performance and adaptability in real-time network environments. Work done in a summer internship at Intel Labs. |

|
A View on Deep Reinforcement Learning in System Optimization
Ameer Haj-Ali, Nesreen Ahmed, Ted Willke, Joseph Gonzalez, Krste Asanovic, Ion Stoica arXiv preprint, 2019. arXiv This paper critically reviews and evaluates the application of deep reinforcement learning to system optimization, proposing key metrics for future assessments and discussing the method's relative effectiveness, challenges, and potential directions compared to traditional and heuristic approaches. Work done in a summer internship at Intel Labs. |

|
AutoPhase: Compiler Phase-Ordering for HLS with Deep Reinforcement Learning
Ameer Haj-Ali, Qijing Huang, William Moses, John Xiang, Ion Stoica, Krste Asanovic, John Wawrzynek FCCM, 2019. paper / arXiv / code / video This paper evaluates a deep reinforcement learning framework implemented in the LLVM compiler to optimize the order of optimization passes for high-level synthesis, achieving a significant enhancement in circuit performance and markedly faster results compared to state-of-the-art phase-ordering algorithms. |

|
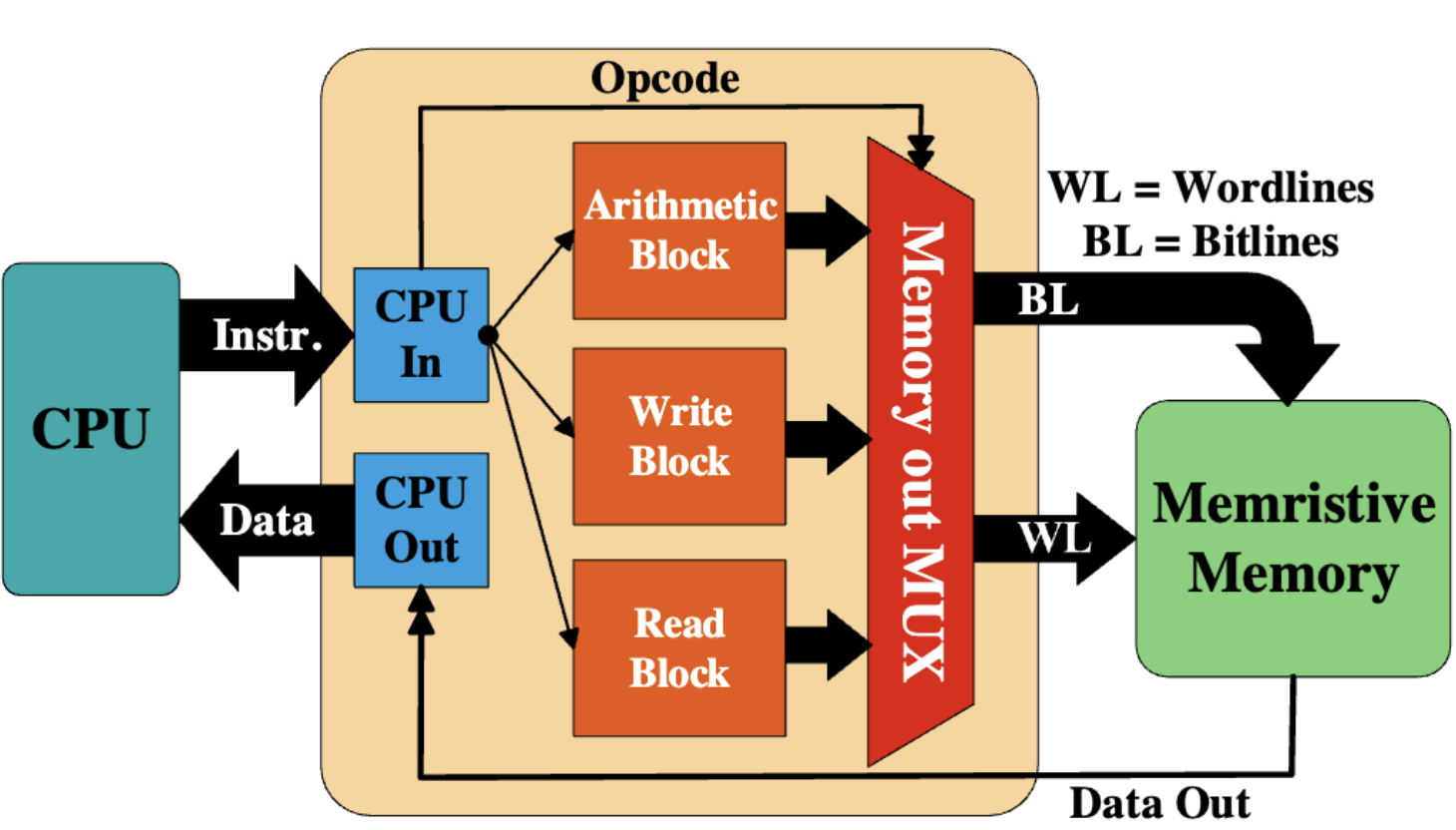
Memristor-Based Processing-in-Memory and Its Application On Image Processing
Ameer Haj-Ali, Ronny Ronen, Rotem Ben-Hur, Nimrod Wald, Shahar Kvatinsky Elsevier, 2020. chapter This chapter overviews memristor-based logic techniques in in-memory computing (IMC), exemplified through a case study on Memristor Aided loGIC (MAGIC) in a memristive Memory Processing Unit (mMPU), demonstrating enhanced performance and energy efficiency in image processing tasks compared to other advanced memristive logic systems. |
|
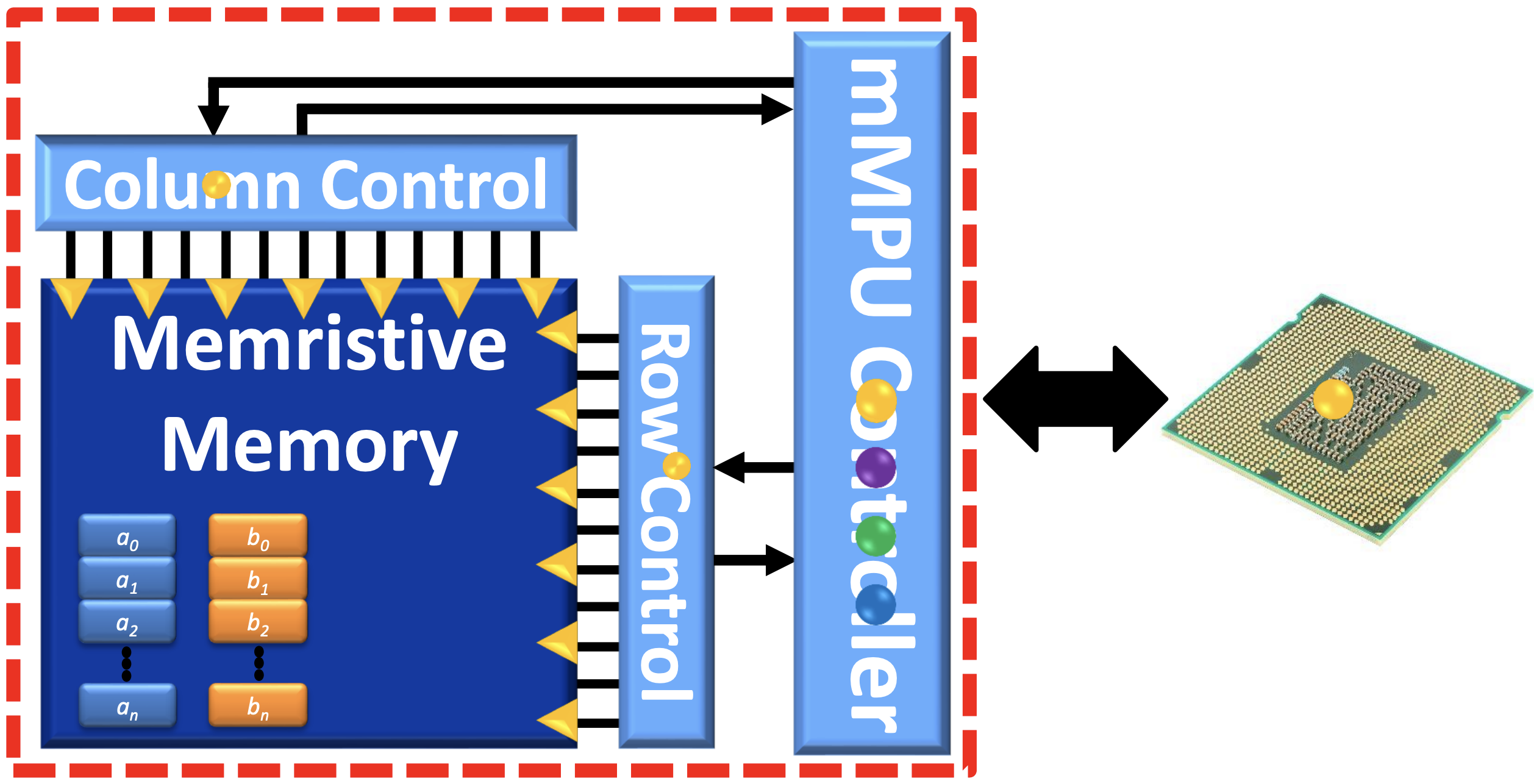
mMPU - a Real Processing-in-Memory Architecture to Combat the von Neumann Bottleneck
Nishil Talati, Rotem Ben-Hur, Nimrod Wald, Ameer Haj-Ali, John Reuben, Shahar Kvatinsky Springer, 2020. chapter This chapter introduces the memristive Memory Processing Unit (mMPU), which integrates computation within memory cells using Memristor Aided loGIC (MAGIC) to address the von Neumann bottleneck, detailing the system's architecture and demonstrating how MAGIC can execute arbitrary Boolean functions for processing-in-memory applications. |

|
SIMPLER MAGIC: Synthesis and Mapping of In-Memory Logic Executed in a Single Row to Improve Throughput
Rotem Ben-Hur, Ronny Ronen, Ameer Haj-Ali, Debjyoti Bhattacharjee, Adi Eliahu, Natan Peled, Shahar Kvatinsky TCAD, 2019. paper This article introduces SIMPLER, an automatic framework that optimizes the execution of arbitrary combinational logic functions within a memristive memory using graph theory, logic design, and compiler technology, achieving substantial improvements in throughput, area efficiency, and parallel processing capabilities for in-memory computing. |

|
Supporting the Momentum Training Algorithm Using a Memristor-Based Synapse
Tzofnat Greenberg-Toledo, Roee Mazor, Ameer Haj-Ali, Shahar Kvatinsky TCAS-I, 2019. paper This paper introduces a memristor-based synapse that enhances deep neural network (DNN) training by supporting the momentum algorithm, proposing two design approaches to improve the convergence and efficiency of training, with simulations showing significant speedups and energy reductions compared to GPU platforms. |
|
Not in Name Alone: a Memristive Memory Processing Unit for Real In-Memory Processing
Ameer Haj-Ali, Rotem Ben-Hur, Nimrod Wald, Ronny Ronen, Shahar Kvatinsky IEEE Micro, 2018. paper This paper presents the memristive Memory Processing Unit (mMPU), a processing-in-memory system that eliminates data transfer by performing computation directly within memory cells, leveraging its inherent parallelism to provide high throughput and energy efficiency for SIMD-based data-intensive applications. |

|
IMAGING: In-Memory AlGorithms for Image processiNG
Ameer Haj-Ali, Rotem Ben-Hur, Nimrod Wald, Ronny Ronen, Shahar Kvatinsky TCAS-I, 2018. paper This paper proposes four in-memory algorithms for fixed-point multiplication using MAGIC gates, implemented within memristor-based memory cells to enhance latency, throughput, and area efficiency, enabling effective execution of complex operations like image convolution and optimized parallel processing in data-intensive applications. |
|
Efficient Algorithms for In-memory Fixed Point Multiplication Using MAGIC
Ameer Haj-Ali, Rotem Ben-Hur, Nimrod Wald, Shahar Kvatinsky ISCAS, 2018. paper This paper introduces algorithms for performing fixed-point multiplication within memristive memory cells using Memristor Aided Logic (MAGIC) gates, achieving a 1.8× improvement in latency and enhanced area efficiency that enables simultaneous executions, addressing the computational constraints of previous implementations. |

|
Practical Challenges in Delivering the Promises of Real Processing-in-Memory Machines
Nishil Talati, Ameer Haj-Ali, Rotem Ben-Hur, Nimrod Wald, Ronny Ronen, Pierre-Emmanuel Gaillardon, Shahar Kvatinsky DATE, 2018. paper This paper evaluates the memristive Memory Processing Unit (mMPU) as a Processing-in-Memory (PiM) machine, analyzing its limitations in parallelism and internal data transfer, and demonstrates that these factors can increase execution times significantly, despite strategies to manage data movement within the device itself. |

|
Memristive Logic: A Framework for Evaluation and Comparison
John Reuben, Rotem Ben-Hur, Nimrod Wald, Nishil Talati, Ameer Haj-Ali, Pierre-Emmanuel Gaillardon, Shahar Kvatinsky PATMOS, 2017. paper This paper introduces a framework for comparing memristive logic families by evaluating their statefulness, proximity to memory arrays, and computational flexibility, providing metrics for performance, energy efficiency, and area, and offering guidelines for a comprehensive assessment to facilitate the development of new logic families. |

|
A Taxonomy and Evaluation Framework for Memristive Logic
John Reuben, Rotem Ben-Hur, Nimrod Wald, Nishil Talati, Ameer Haj-Ali, Pierre-Emmanuel Gaillardon, Shahar Kvatinsky Springer, 2017. chapter This chapter outlines a framework for evaluating memristive logic families based on their statefulness, proximity to memory, and computational flexibility, using metrics for latency, energy efficiency, and area, and includes a case study on eight-bit addition to demonstrate the methodology and assess the potential for large-scale data computation. |
Miscellanea |

|
Area Chair: NeurIPS 2024, NeurIPS 2023, NeurIPS 2022
Conference & Journal Referee: NeurIPS 2019, HPCA 2018, DATE 2018, VLSI-SoC 2018, ISCAS 2017, ISCAS 2016, CNNA 2016, TCAS-I, TCAS-II, TVLSI, Microelectronics Journal |

|
Academia and Teaching
Graduate PhD Admissions Committee DARE (Diversifying Access to Research in Engineering) Admissions Committee. Undergraduate project committee Graduate Student Instructor (GSI), Introduction to Machine Learning (CS 189/289A) Head TA, Circuit Theory (700+ students, 044105). Head TA, Electronic Switching Circuits (300+ students, 044147). Supervisor of B.Sc. projects, VLSI Lab and Parallel Systems Lab (044167). TA, MATLAB (044147). |

|
Advised Students
Chloe Liu (First employment: graduate student at Stanford). Ian Galbraith (First employment: software engineer at Twilio). Fang Shuo Deng (First employment: software engineer at Abnormal Security). Stav Belogolovsky (First employment: Test and DFT Engineer at Arbe). Amnon Wahle (First employment: Algorithm Research at BeyondMinds). |

|
Awards and Fellowships
The person of the year in my home city (45,000 residents), Shefaraam, 2022. Granted the EB1 + Green Card (Einstein Visa for Extraordinary Ability), USA, 2021. Granted the O1 extraordinary ability Visa, USA, 2020. The Valedictorian Honor (M.Sc.), Technion, 2019. Open Gateway Fellowship, UC Berkeley, 2018. The William Oldham Fellowship, UC Berkeley, 2018. The Valedictorian Honor (B.Sc.), Technion, 2017. Dean's scholarship for excellent graduate students, Technion, 2016. Full tuition scholarship for M.Sc. studies, Technion , 2016-2018. The System Architecture Labs Cluster Prize for outstanding undergraduate projects (received twice), Technion, 2016. Excellence award from Apple for excellent scholastic achievements, Technion, 2016. Member of the President's List of highest honors for excellent scholastic achievements in all undergraduate semesters (top 3%), Technion, 2013-2016. Full tuition scholarship for B.Sc. studies, Technion, 2013-2016. |

|
Blog Posts
Cloud Infrastructure for LLM and Generative AI Applications Anyscale Endpoints Preview: Fast, Cost-Efficient, and Scalable LLM APIs Autoscaling clusters with Ray Easy Distributed Scikit-Learn with Ray Scale ML on Your Local Clusters with Ray |
|
|